Generate Output Stage based on Existing Logical Data Model
You can now generate the Output Stage based on the logical data model (LDM) in your project when setting up direct data distribution from a data warehouse (for example, Snowflake or Amazon Redshift).
Generating the Output Stage based on an existing LDM can help you deploy the direct data distribution much faster in the situation when you already have a GoodData project with the LDM that meets your business requirements for data analysis and which you do not want to update.
In this case, using the LDM as a basis for generating the Output Stage will help you save time and effort.
What other options are available?
You can generate the Output Stage based on the Data Source and the database schema stored in it. Then, you would generate the LDM for your project based on the Output Stage.
This approach works best when you do not yet have a GoodData project or want to generate/update the LDM to best fit the existing data structure in your data warehouse. For more information, see API: Generate the Output Stage based on the schema.
How can you generate the Output Stage based on the LDM?
Use the following API to get SQL DDLs that you can then use to create GoodData-compatible views/tables:
https://secure.gooddata.com/gdc/dataload/projects/{project_id}/generateOutputStage
NOTE: If you are a white-labeled customer, replace secure.gooddata.com with your white-labeled domain.
For all the details about this API, see API: Generate the Output Stage based on the LDM.
Learn more:
API: Generate the Output Stage based on the LDM
Integrate Data Warehouses Directly to GoodData based on Your DW Schema
CSV Downloader: Certificate-Based Authentication for SFTP Locations
We have updated the way of how CSV Downloader authenticates to the SFTP server, from which you want to download data, when certification-based authentication mode is used.
If you use an SFTP location to store your source data and want to use certification-based authentication, set the auth_mode parameter to cert in the configuration file:
"csv": {
"type": "sftp",
"options": {
"username": "{sftp_email@address.com}",
"host": "{sftp_hostname}",
"auth_mode": "cert"
}
}
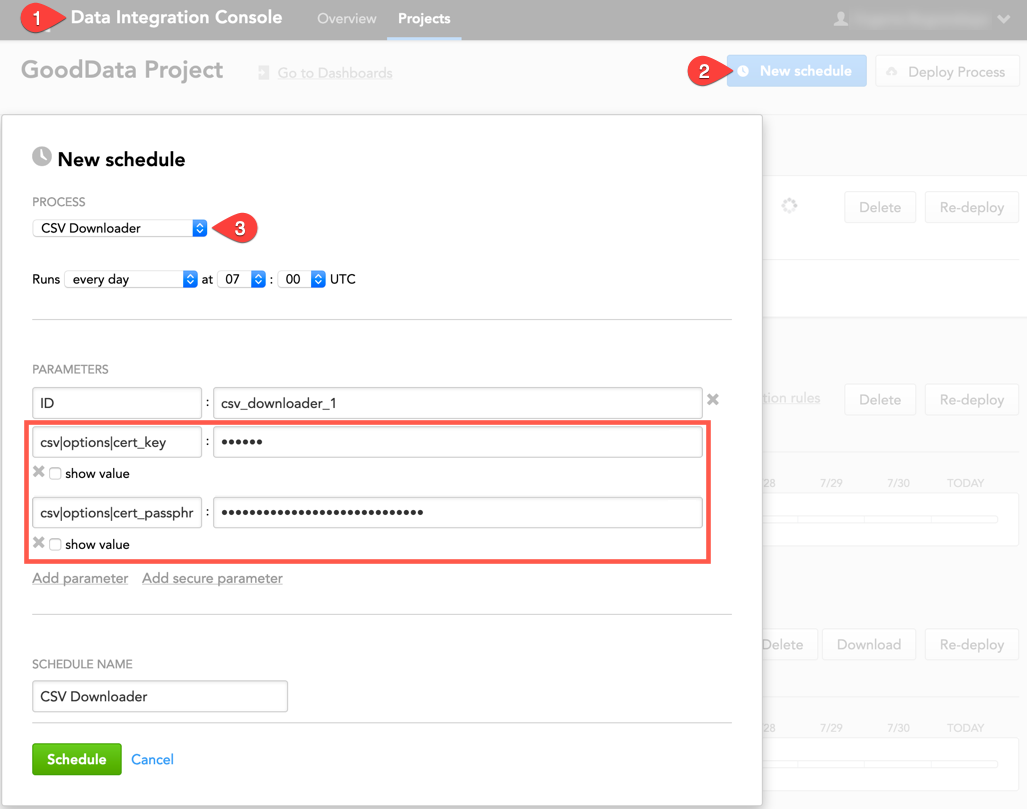
When scheduling a process for CSV Downloader in the Data Integration Console, provide the private key (as the csv|options|cert_key secure parameter). If the private key is encrypted, also provide the passphrase to decrypt the private key (as the csv|options|cert_passphrase secure parameter).
Learn more:
CSV Downloader
SQL Downloader: New Default Value for "fetch_size"
When you are using SQL Downloader to download data from a PostgreSQL database, the fetch_size parameter now defaults to 50,000. Before, it did not have a default value (and this is still true for the other supported databases in SQL Downloader).
fetch_size is an optional parameter that allows you to customize the database connection by setting up the number of rows to fetch from the database when more rows are needed.
"sql": {
"type": "PostgreSql",
"options": {
"connection": {
"server": "{server_address}",
"database": "{database_name}",
"username": "{user_name}",
"fetch_size": number_of_rows // optional, defaults to 50.000
}
}
}
Keeping fetch_size at its default helps you prevent out-of-memory or performance issues. If you want to use a different value, avoid setting fetch_size to a small number (for example, 50).
Learn more:
SQL Downloader
Download Apache Parquet Files with COPY FROM S3 Command
You can now use the COPY FROM S3 command to download Apache Parquet files from an Amazon S3 bucket to your Data Warehouse instance.
COPY {table_name} FROM 's3://{bucket}/{file}.parquet' PARQUET;
Learn more:
Use COPY FROM S3 to Load Data
Data Warehouse Upgrade to Vertica 9.2.1 Completed
We have completed upgrading the Vertica software on our Data Warehouse. It now runs on Vertica Version 9.2.1. You can find detailed information about Version 9.2.1 in Vertica's online documentation. We have updated the user documentation for our Data Warehouse accordingly.