Heatmap - New Insight Type in Analytical Designer and KPI Dashboards
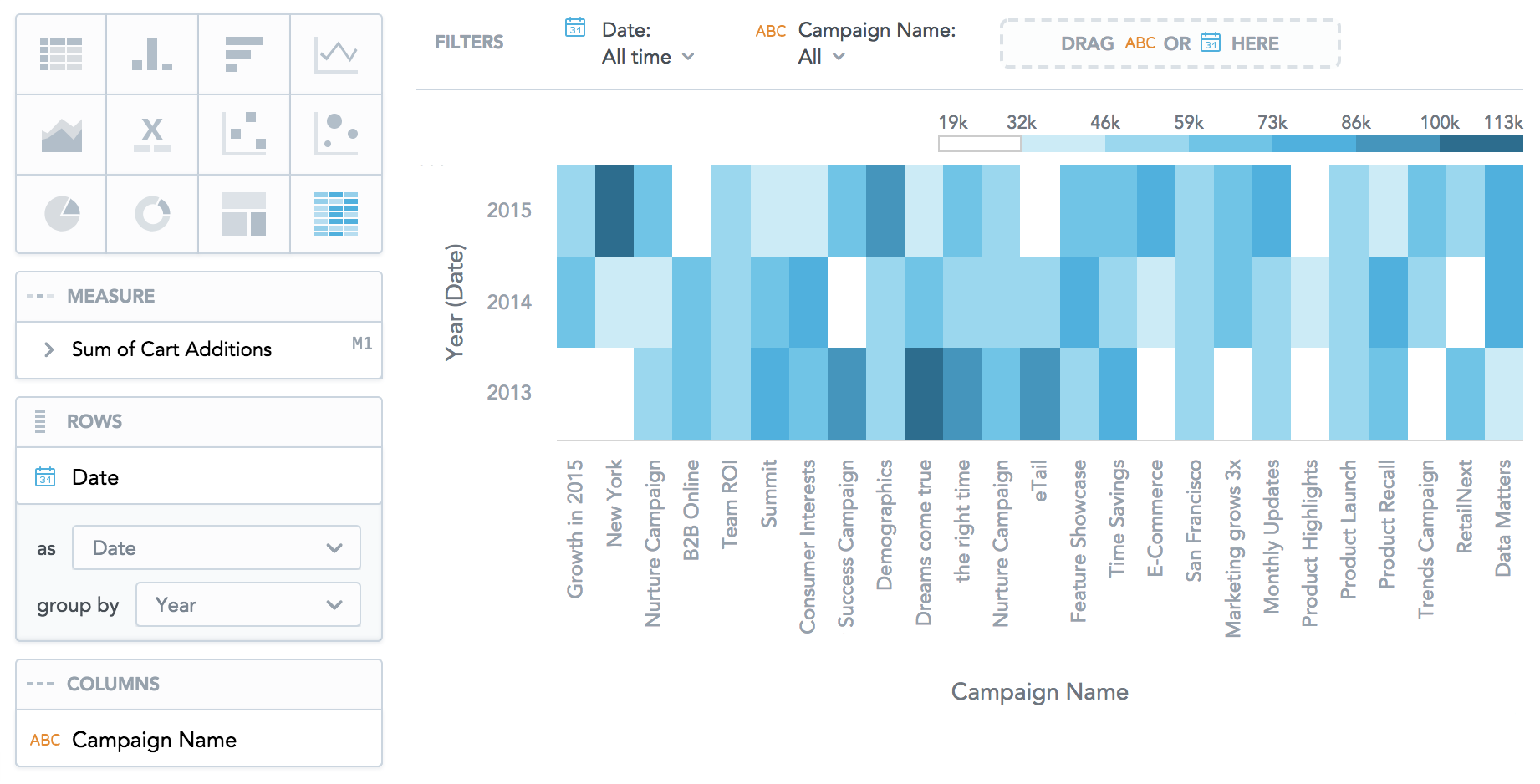
In Analytical Designer, you can now create heatmaps.
Heatmaps display data as a matrix where individual values are represented as colors. You can use heatmaps to discover trends and understand complex datasets.
Learn more:
Heatmaps
Insight Types in Analytical Designer
New Load Mode in Automated Data Distribution
When uploading data to projects using Automated Data Distribution (ADD), you can now use UNRESTRICTED load mode in the executed data load process. UNRESTRICTED load mode allows you to customize your data loading strategy, to make it even more flexible, and to decrease data latency in your projects.
UNRESTRICTED mode is available for executing ADD data load processes via the API.
When can you benefit from UNRESTRICTED mode?
With UNRESTRICTED mode, you can split a data load increment into multiple tasks and upload the data in portions in a specific order so that the most relevant data is available in your projects as soon as possible. UNRESTRICTED mode lets you prioritize data to upload.
For example, you may want to first upload the data about your premium customers so that you can analyze it first, and then you can proceed with the rest of the data. Or, you may want your end users to first see the most recent data (let's say, for the last month), and you can load the older data later.
How does UNRESTRICTED mode work?
In addition to specifying load mode per dataset (as CUSTOM load mode already allows), you can also specify additional parameters. For example, the condition parameter lets you define a condition to enrich the SQL fetch query and narrow down the data selected from the ADD output stage:"condition": "a__company=ACME""condition": "d__date BETWEEN '2018-12-01' AND '2018-11-01'"
Are there any access rights required?
To be able to use UNRESTRICTED mode, you must have access to the Data Warehouse instance that is set in the ADD output stage for the project.
WARNING: UNRESTRICTED mode is intended only for experienced users. You should use UNRESTRICTED mode only if you are confident in executing the schedule via the API and have a deep understanding of your data. Using UNRESTRICTED mode incorrectly or with wrong parameters may result in data inconsistency in your projects. If you are not sure whether to use UNRESTRICTED mode, we recommend that you use DEFAULT or CUSTOM mode.
Learn more:
Automated Data Distribution
API: Execute a schedule
New API and Introducing API Versioning
List user projects and roles now allows paging and with this GoodData's public API is introducing versioning. This allows GoodData to release new API without breaking existing clients for the purposes of deprecation and end-of-life of old API. GoodData API versioning will not break existing clients without giving you a chance to adapt the newer API.
Learn more:
API Versioning information and Changelog
GoodData API - List user projects and roles
Data Preparation and Data Evaluation Functions Available in Data Warehouse
Data Warehouse now supports preprocessing and postprocessing functions to simplify data transformations for Machine Learning.
You can use the following Vertica functions in Data Warehouse:
- Data preparation functions
- APPLY_NORMALIZE - Applies the normalization parameters saved in a model to a set of specified columns in the input table or view.
- BALANCE - Balances the data.
- DETECT_OUTLIERS - Removes the outliers from the data.
- IMPUTE - Imputes missing values with either the mean or the mode, based on observed values for a variable.
- NORMALIZE - Runs a normalization algorithm on an input table or view.
- NORMALIZE_FIT - Computes normalization parameters for specific columns in an input table.
- REVERSE_NORMALIZE - Reverses the normalization transformation.
- Data evaluation functions
- CONFUSION_MATRIX - Returns a confusion matrix based on both predicted and observed values.
- ERROR_RATE - Returns a table that calculates the rate of incorrect classifications.
- LIFT_TABLE - Returns a table that compares the predictive quality of a binary classifier model.
- MSE - Returns a table that displays the mean squared error.
- ROC - Returns a table that displays the points on a receiver operating characteristic curve.
- RSQUARED - Returns a table with the R-squared value of the predictions in a linear regression model.
Learn more:
Data Preparation and Data Evaluation Functions
Set Fixed Headers and Include Filter Context in Excel Exports
Admins may set a fixed customer headers for Excel exports. Each sheet may contain up to five top rows with text or using macros (date, time, project id etc.)
Also when exporting to XLSX, you can include active filters in the exported file for each exported report.
Learn more:
Export File Types
Configure Custom Headers for XLSX Report Exports
API reference
UPCOMING: Dates Are Exported to XLSX as Date Data Types
Previously, all dates in your reports were transformed into strings during the export to XLSX.
With the next release, the dates will be exported as date data types so that you can further analyze all the data.
If you are using, for example, any custom macros based on strings, make sure to update them for the next release.
REMINDER: Upcoming End-of-life of JDBC Driver Version 2.8.0 through 2.9.0
On October 4, 2018, the JDBC driver version 2.8.0 through 2.9.0 will stop working.
Please note that we have postponed the date from September 20, 2018, to October 4, 2018. However, If you are using version 2.8.0 through 2.9.0 of the JDBC driver, we strongly recommend that you upgrade to the latest version, 3.1.2, as soon as possible.
How will this affect you?
If you are using version 2.8.0 through 2.9.0 of the JDBC driver, it will stop working on October 4, 2018. You will receive the following error message:
You are using an unsupported version of the JDBC driver.
Download and install the latest version of the driver itself or
CloudConnect from https://secure.gooddata.com/downloads.html.
Action needed:
Before October 4, 2018, check the version of your JDBC driver.
If your version is 2.8.0 through 2.9.0, upgrade to the latest version, 3.1.2:
- If you are using the driver directly, download and install the latest version of the driver from the Downloads page.
- If you are using the driver via CloudConnect, upgrade your CloudConnect to the latest version: from the menu bar, click Help -> Check for Updates.
We will post a separate announcement when the end-of-life happens for the JDBC driver version 2.8.0 through 2.9.0.
Learn more:
For more information about the end-of-life rules for the JDBC driver, see Data Warehouse Driver Version.